作者:孙显鹏
故障描述:
多节点oracle RAC 11204环境下,分布式存储硬件检修后需要online磁盘,执行alter diskgroup ocr online disk OCR_0000,online命令hang,长时间没有反应,检查asm日志无报错信息。查询mos 可能遭遇了bug ID:1232398.5,ASM在集群范围有锁。
查询ASM集群范围锁信息如下:

SQL> select sql_text from v$sql where sql_id=’cx9y8a6kn1g5v’;
SQL_TEXT
—————————-
alter diskgroup ocr online disk OCR_0000
可以看到1648 session 正是我们online命令,等待KSV master wait事件和bug描述一致。
另外发现1709 session 等待DFS lock 被3号节点2319 session阻塞。
检查3号节点的2319 session,发现被1号节点的977 session阻塞,同样等待DFS LOCK。
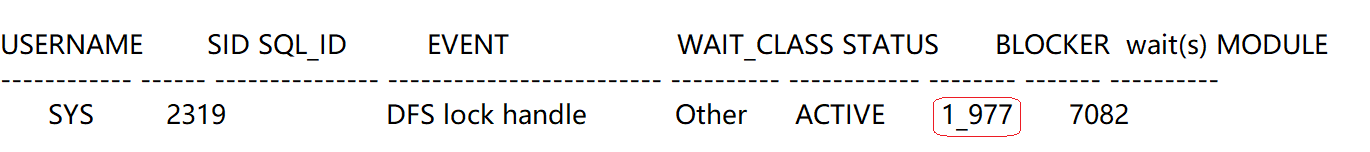
2319 session 在做什么呢?
2319 在执行asm磁盘 rebalance 操作,检索asm日志发现该rebalance 操作是下午执行 alter diskgroup ocr rebalance power 8 命令触发的。
日志信息类似如下:
NOTE: ASM did background COD recovery for group 4/0xaac86b7a (OCR)
NOTE: starting rebalance of group 4/0xaac86b7a (OCR) at power 8
Starting background process ARB0
从这里也可以明白上面这个命令会触发rebalance操作,正确的做法应该是修改power 参数。
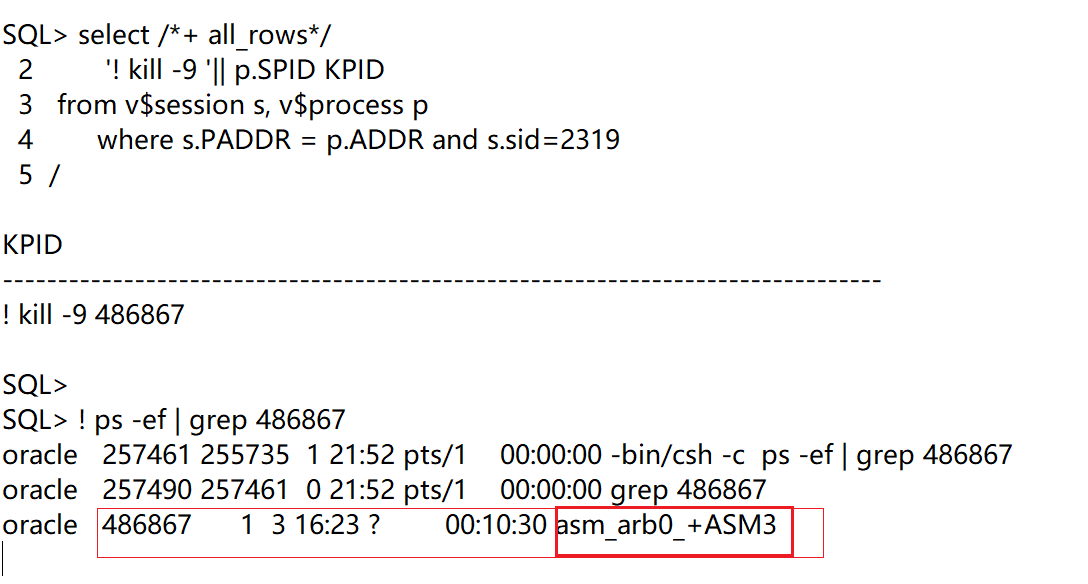
那么这个 rebalance 为何如此长时间没有平衡结束呢?而且也没有实际发生平衡操作。从上面的分析其实已经看出来了,因为1号节点977 session 阻塞了该rebalance 操作。继续分析1号节点的977 session:

977 是检查点进程。
一般遇到检查点阻塞问题,首先考虑刷新内存,该case刷新内存后问题依旧。
从上面的bug 信息中 oracle的建议是重启asm实例。为了最小范围影响业务,决定重启最终的阻塞者1号节点的asm实例。经过和客户商定最终重启了1号节点asm实例。再次观察asm集群等等发现,rebalance 成功执行,再次执行online 操作也成功。
问题还没有结束,那么从这个bug的描述可以看到该bug 在11204上已经修复了,那么为什么客户的环境遇到了该问题呢?继续检查发现下面信息:

原来客户的数据库兼容性设置太低。为了彻底修复该问题建议客户修改数据库兼容性参数为11.2.0.4.0
结束语:ASM 锁和其他锁的原理是相同的,但是一旦遇到可能会造成非常严重的后果。比如可能会导致整个集群io全部阻塞,集群宕机。本次提到的case中asm锁算是一个轻量级的锁。从问题的处理过程可以看到asm锁和其他锁的处理方式是一样的,都是找到最终的阻塞者解除锁即可。